Dr. Michael Shekelyan, Computer Science Researcher
Bio
I was born in Moscow, but I grew up in Hamburg and then later moved to Munich where I studied and worked with Prof. Matthias Schubert and Prof. Hans-Peter Kriegel's database group (University of Munich). I did my PhD in Italy under the supervision of Prof. Johann Gamper (Libera Università
di Bolzano) and then went to the UK for postdoctoral research under Prof. Graham Cormode (University of Warwick) & Dr. Grigorios Loukides (King's College London) followed by working as a Lecturer in Computer Science (Queen Mary & Westfield College, University of London).
Research
My research focuses
primarily on algorithms, data structures and summaries to manage very large or sensitive data.
The overall goal is to build a full data pipeline that feeds end users with easily interpretable facts
which provide novel insights and aid decision making processes.
Reducing the data complexity either through sampling or summarisation plays a crucial
role to support exploratory interactions with the data that involve a lot of probing,
while still providing an intuitive approximation model of the data.
Sensitive data calls for privacy-preserving techniques such as differential privacy & federated learning to facilitate data sharing between organisations whilst minimising risks to the privacy of patients, users, customers and employees whose personal information is collected.
Differential Privacy
How to select the top items based on sensitive scores in a privacy-preserving manner:
How to collect a (weighted) random sample over a huge table that is only available as a set of smaller linked tables that need to be joined together (requiring just one pass over most troublesome table):
referenced in:
Dissertation, University of Warwick [2022]
PVLDB [2023]
DEXA [2024]
Modern Pathology [2024]
Complex Networks & Their Applications [2023]
Computational Intelligence and Neuroscience [2022]
arXiv [2022b, 2022c]
Shany came up with the really cool idea of posing join sampling via probabilistic graphical models:
Shanghooshabad, Kurmanji, Ma, Shekelyan, Almasi & Triantafillou
PGMJoins: Random Join Sampling with Graphical Models
ACM SIGMOD (2021) [conference, bibtex, link]
referenced in:
Dissertation, University of Minnesota [2022]
Technical Report, Oregon State University [2022]
ACM SIGMOD [2022, 2023, 2024, 2024b]
ACM PODS [2023]
PVLDB [2023]
EDBT [2023a]
IEEE TKDE [2024]
ACM Management of Data [2023, 2024]
ACM EdgeSys [2022]
ACM SoCC [2023]
ACM HILDA [2023]
arXiv [2022b, 2022c, 2023]
Multidimensional Data Summaries
How to build tiny data models that empirically tend to be good at approximating the number of points in a rectangular range
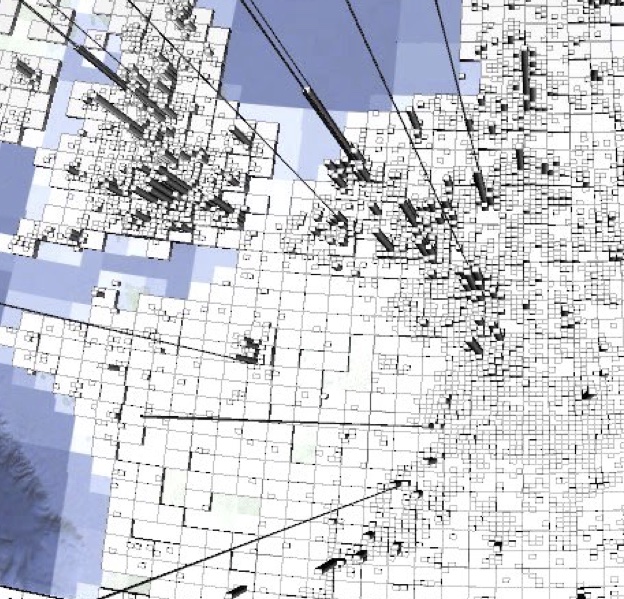
DigitHist summary of spatial data
(zoomed in on UK and Germany)
:
Shekelyan, Dignoes & Gamper
DigitHist: a Histogram-Based Data Summary with Tight
Error Bounds
PVLDB (2017) [conference, link, slides, bibtex, pdf]
referenced in:
Dissertation, Technical University of Munich [2020, 2023]
Dissertation, University of Edinburgh [2022]
Dissertation, University of Mannheim [2022]
Dissertation, Hong Kong Polytechnic University [2019]
Dissertation, Indian Institute of Science [2019]
ICLR [2024]
PVLDB [2018, 2019, 2020, 2024]
IEEE ICDE [2021, 2021b, 2021c]
EDBT [2023b]
CIDR [2019]
IEEE TKDE [2019, 2023]
Data Science and Engineering [2018]
Knowledge and Information Systems [2020, 2021]
Information Systems [2022]
IEEE Transactions on Industrial Informatics Systems [2024]
Journal of Information Processing [2024]
arXiv [2023, 2024]
How to build compact data models that are theoretically guaranteed to be good at approximating the number of points in a rectangular range (not just asymptotically!):
Shekelyan, Dignoes, Gamper & Garofalakis
Approximating Multidimensional Range Counts with Maximum Error Guarantees IEEE ICDE (2021) [conference, bibtex, pdf]
How to compute sums over sub-tables for a very large table of numbers, most of which are equal to zero :
Shekelyan, Dignoes & Gamper
Sparse prefix sums: Constant-time range sum queries over sparse multidimensional data cubes
INFORMATION SYSTEMS (2019) [journal, slides, bibtex, link]
referenced in:
Nucleic Acids Research [2024]
arXiv [2021]
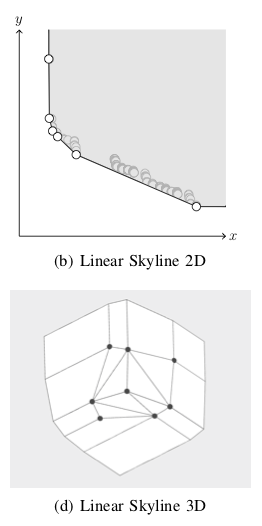
How to find all paths between two network nodes that could be best for some user preference
Shekelyan, Josse & Schubert
Linear path skylines in bicriteria networks
DASFAA (2014) [conference, link, project, bibtex, pdf]
referenced in:
Dissertation, University of Munich [2016, 2016b]
Dissertation, University of Alberta [2017, 2020]
Dissertation, Technical University of Dortmund [2018]
IEEE ICDE [2015, 2015b]
ACM SIGSPATIAL [2017, 2017b, 2017c, 2020, 2020b]
SSTD [2015, 2015b, 2015c, 2017]
IEEE MDM [2020, 2021]
EMO [2017]
VEHITS [2016]
IPSI Bgd Transactions on Internet Research [2024]
Journal of Internet Technology [2019]
IET Intelligent Transport Systems [2019]
Journal of Big Data [2023]
Information Systems [2016]
ACM Transactions on Spatial Algorithms and Systems [2020]
IPSI Transactions on Internet Research [2024]
Geoinformatica [2017, 2018]
Shekelyan, Josse & Schubert
ParetoPrep: Efficient Lower Bounds for Path Skylines and Fast Path Computation
SSTD (2015) [conference, link, project, bibtex, pdf]
referenced in:
Dissertation, University of Munich [2016, 2016b]
Dissertation, Technical University of Dortmund [2018]
ACM SIGSPATIAL [2017c]
ACM SIGSPATIAL IWCTS workshop [2024]
SSTD [2015b, 2015c, 2015d]
EMO [2017]
Geoinformatica [2017]
Shekelyan, Josse & Schubert
Linear path skylines in multicriteria networks
IEEE ICDE (2015) [conference, link, project, bibtex, pdf]
referenced in:
Dissertation, University of Munich [2016]
Dissertation, University of Technology Sydney [2019]
Dissertation, New Mexico State University [2021]
Dissertation, Université de Bordeaux [2021]
IEEE ICDE [2019, 2020]
EDBT [2018]
ACM SIGSPATIAL [2015, 2017c, 2018, 2024]
ACM SIGSPATIAL IWCTS workshop [2023]
SSTD [2015b, 2015c]
DASFAA [2018, 2023]
IEEE MDM [2021]
IEEE HPCC / SmartCity / DSS [2016]
IEEE LifeTech [2021]
IEEE Transactions on Spatial Algorithms and Systems [2024]
ATMOS [2020]
Mathematical Problems in Engineering [2018]
Geoinformatica [2017]
Websites
How do we turn computer "science" into computer science? [link]
How do we get fewer papers with more quality? [link]
London Nightvoucher Project
Currently just an idea born out of my own experiences living in London. I am still learning more about the intricacies involved and potential stumbling blocks ahead, but let me know if you are in any way interested in making it easier to make dedicated donations towards accommodation for people sleeping rough. More details can be found on the project website [nightvoucher.org.uk].
Note: The views and opinions expressed on this site are those of the authors and do not necessarily reflect the official policy or position of their employers. [back]

 Teaching / Research Positions
Teaching / Research Positions